
Small language models : between speed and relevance
Small LanguageModels (SLMs) are an attractive alternative to Large Language Models (LLMs). They are particularly attractive because of their speed of execution and low hardware resource requirements. They take much less time to evaluate prompts and generate responses. This enables smoother integration into real-time systems, low-resource applications and those requiring intensive calls to these models.
Their limits
However, this speed is often achieved at the cost of compromising on the relevance and quality of responses. These compromises are measured by benchmarks such as MMLU (Massive Multitask Language Understanding) or MT-Bench (Multi-Turn Benchmark). This poses significant challenges for researchers and developers seeking to optimize both speed and relevance.
A fundamental fundamental
In order to make the most of the compromise described, when integrating the language model into a product architecture, it is necessary to know the strengths and weaknesses of each.
In order to compare the language models, we have placed ourselves in the use case where the speed of response production is paramount.
Depending on the hardware and software architecture used to deploy language models, or on the type of application, performance can vary greatly. For this reason, the study we are about to present is valid only for the architecture and conditions for which it was built.
We propose a visualization of the compromise we have obtained for the best small language models available today (October 28, 2024).
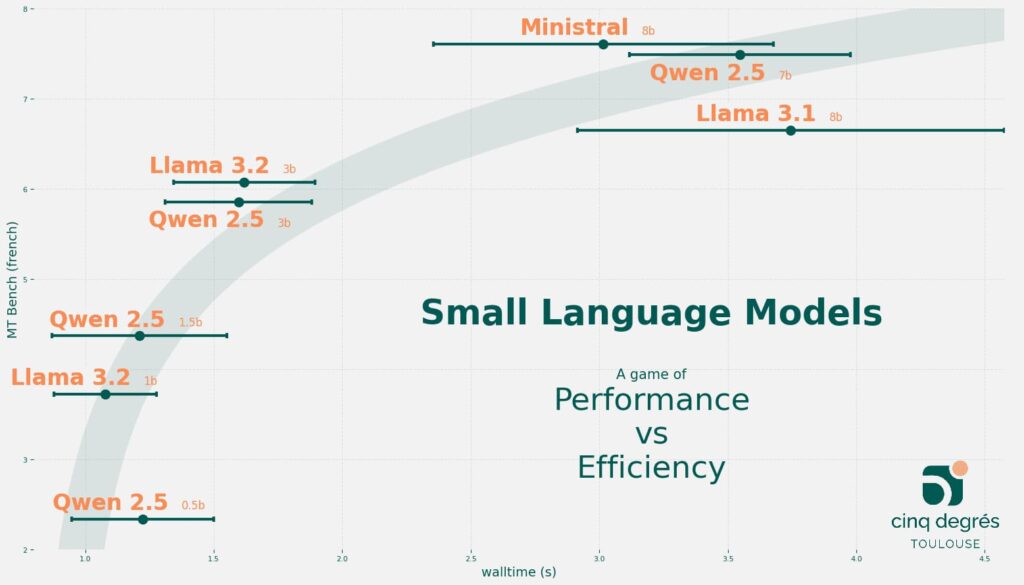
The total time represented on the x-axis above is the sum of the prompt evaluation time and the total prompt response generation time.
Many factors can influence the total response time of the language model, such as the hardware resources used (CPU or GPU), the software architecture, etc...
To find out more about our calculation method and/or obtain this type of graph applied to your specific use case, please contact us!
A visualization to adapt
Introducing the MT-Bench score
This is a performance indicator used to assess the ability of language models to manage conversations consisting of successive responses. In other words, it measures their ability to understand context and provide relevant responses over several consecutive exchanges. This is essential for natural, coherent interactions. This benchmark takes into account criteria such as coherence, relevance and the ability to maintain conversational context.
Its limits
Like all measures of language model quality, the MT-Bench score has its limits. It's important to note that some models can be further optimized to achieve a better score on this benchmark, without this being indicative of better quality.
We used the MT-Bench score specific to French-language exchanges. This measure is often highly relevant to our current applications. Your use case will certainly have its own specificities, which will need to be taken into account when adapting the relevance measure.
In particular, one avenue for optimization lies in adapting SLMs to specific tasks. Rather than using generic models capable of answering any type of query, it is possible to focus on models specialized on restricted domains. It is also possible to adapt a generic model to a specific use case. This improves the relevance of responses in a particular domain, while maintaining high execution speed. This practice is called fine-tuning.
Other avenues for acceleration
The evolution of model compression techniques, such as quantification or knowledge distillation, also offers interesting prospects. These techniques make it possible to reduce the size of models while retaining a significant proportion of their relevance. Research in this field is booming. In the near future, advances could make it possible to reduce the gap between the speed of SLMs and the relevance of LLMs.
Do you have similar needs? 5 Degrés can help you with your Product Data issues .

Mathis GERMA
Data Scientist Consultant


