
We live in an environment surrounded by artificial intelligence: personal assistants, automatic translators, intuitive keyboard input on our smartphones... All these technologies are based on Natural Language Processing ( NLP) techniques.
NLP is a fast-growing, multi-disciplinary field at the crossroads of Machine Learning and Linguistics, focusing on the interaction between computers and humans in natural language.
NLP is used in a wide range of applications, such as chatbots, sentiment analysis, language translation and speech recognition. NLP technologies are used incountless sectors to help understand text documents and extract key information from them. In this article, we'll look at some basic NLP techniques for analyzing and understanding natural language.
The tokenization
Tokenization is the process of breaking down a text into individual units, usually words or sentences. These units are called "tokens". Tokenization is a crucial step in NLP, as it simplifies the data for analysis. Different methods are used, such as white space tokenization, regular expression tokenization and rule-based tokenization.
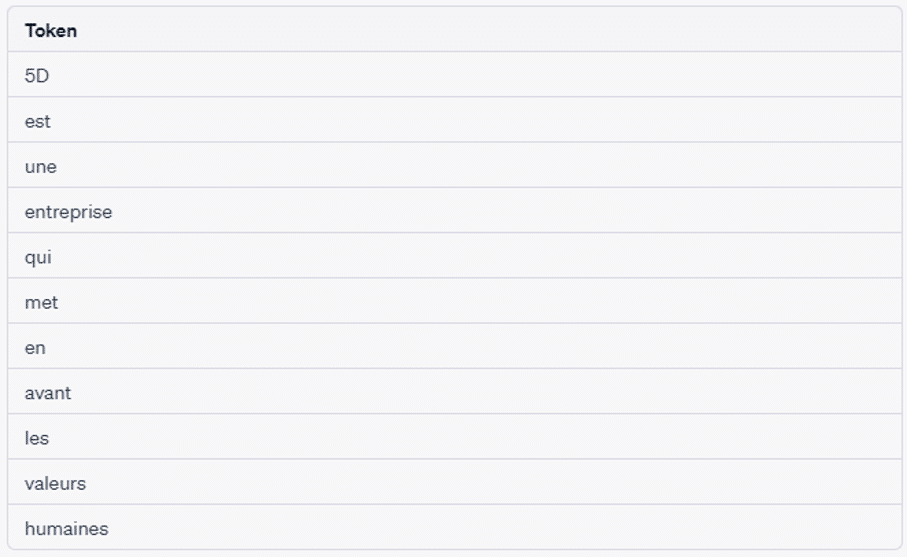
Example: "5D is a company that promotes human values".
The deletion of empty words
Blank words are words that don't make much sense in a sentence, such as "the", "a"and "one". In NLP, empty words are generally removed from the text because they can cause noise and affect the accuracy of the analysis. There are many libraries that provide predefined lists of empty words in different languages, which can be used to remove them from the text.
Example: "5D is a company that promotes human values".
Removal of blank words: "5D entreprise met valeurs humaines".
Enumeration and lemmatization
Stemming and lemmatization are techniques used to reduce words to their basic form. Truncation involves removing suffixes from a word , reducing it to its root form by removing any suffixes or prefixes. For example, the root form of the word "danser" would be "danse". Lemmatization, on the other hand, involves reducing words to their basic form (as in a dictionary), taking into account the part of speech. For example, the lemma for the word "course" would be "cour". Unlike truncation, lemmatization not only removes suffixes and prefixes, but also analyzes the word based on the POS (part of speech), thus taking into account the context in which the word is evoked. In addition, lemmatization reduces the word to a form that can be found in a dictionary.
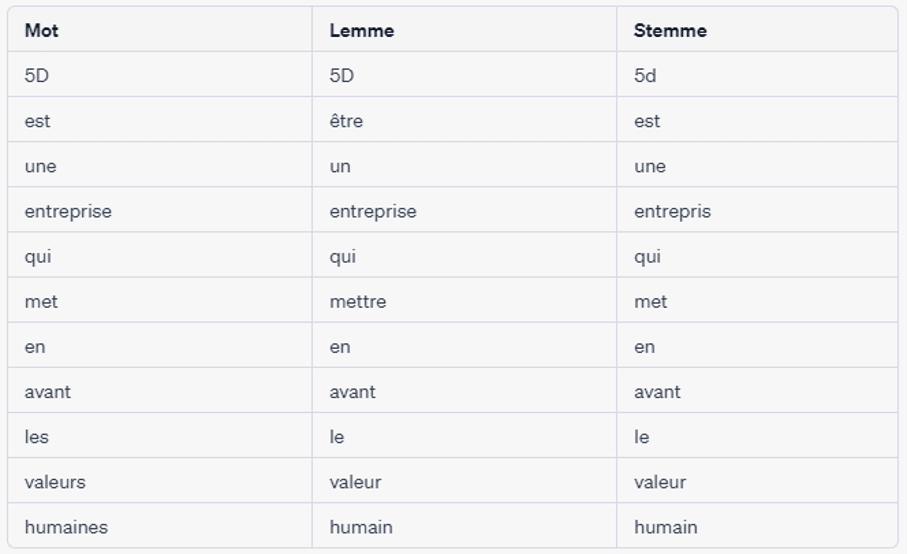
Example: "5D is a company that promotes human values".
Recognition of named entities
Named Entity Recognition (NER) is a technique used to identify and extract entities such as people, places and organizations from text. NER can be used to extract information from large volumes of text, such as news articles or social media posts. NER can also be used for sentiment analysis, as the identification of named entities can provide a context for the sentiment expressed in a sentence.
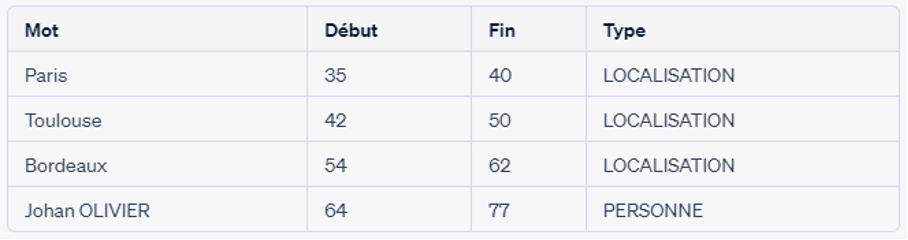
Example: "5D is a company based in Paris, Toulouse and Bordeaux, Johan OLIVIER is one of its Directors".
Labeling the part of speech
Part-of-speech ( POS ) labeling is the process of labeling each word in a sentence with the corresponding part of speech. Parts of speech include nouns, verbs, adjectives, adverbs and pronouns. POS tagging is used to extract information about the structure of a sentence, which can be used in applications such as text-to-speech and machine translation.
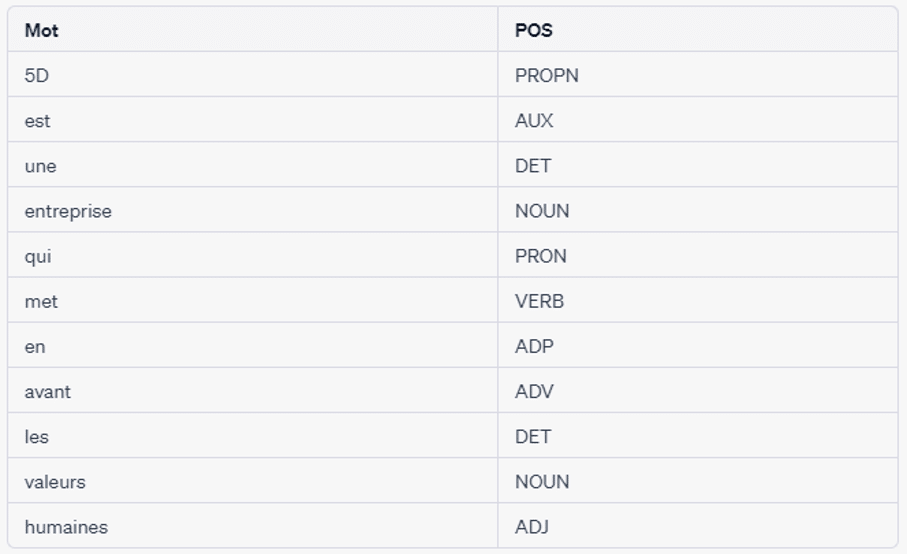
Example: "5D is a company that promotes human values".
Some useful useful :
Vector representation
Lexical extension, also known as Word Embedding, encodes all the semantics of a vocabulary term (lexicon) in the form of a real vector. These vectors are the result of unsupervised learning on a large quantity of textual data. There are two types of approach for this purpose: Bag of Words learns the semantics of a word from its evocation context (i.e. the words surrounding it). Whereas the Skip Gram approach predicts a word's context.
Sentiment analysis
Sentiment analysis is the process of analyzing a text to determine the sentiment expressed in it. Sentiment analysis is used in applications such ascustomer satisfaction analysis (customer reviews) oranalysis of content published on social media (detection of hate speech or racism). Sentiment analysis techniques include rule-based, machine-learning and lexicon-based techniques.
At 5 Degrés, we work with our customers to enrich their metadata.
Here's an example: we were involved in setting up solutions for the automatic analysis of news feeds for press agencies and newspapers. Their challenge was to process large quantities of information in real time.
Do you have similar needs? Are you looking for a partner you can trust to help you solve your Data challenges? Then contact us!
FAQ - The NLP Techniques
NLP enables machines to understand, analyze and generate human language. It is used in voice assistants, chatbots, sentiment analysis, text classification and machine translation.
Not necessarily. Accessible libraries such as SpaCy, NLTK or HuggingFace allow you to experiment without extensive expertise. Understanding the basics is enough to get you started.
Model bias, rough understanding of context, difficulties with cultural nuances and the need for large amounts of data for training.
This depends on the objective: classification, entity extraction, automatic summarization, text generation... Each use has its own adapted models.

Amine Medad
Consultant Data Scientist Practice Product Data


