
Nous vivons dans un environnement entouré d’intelligence artificielle ; assistant personnel, traducteur automatique, saisie intuitive du clavier de nos smartphones… Toutes ces technologies sont basées sur des techniques du Traitement du Langage Naturel ou Natural Language Processing (NLP) en anglais.
Le NLP est un domaine pluridisciplinaire en pleine expansion à la croisée de l’apprentissage automatique (Machine Learning en anglais) et la linguistique, qui se concentre sur l’interaction entre les ordinateurs et les humains en langage naturel.
Le NLP est utilisé dans un large éventail d’applications, telles que les chatbots, l’analyse des sentiments, la traduction des langues et la reconnaissance vocale. Les technologies NLP sont utilisées dans d’innombrables secteurs pour aider à comprendre les documents textuels et à en extraire des informations clés. Dans cet article, nous aborderons quelques techniques de base du NLP pour analyser et comprendre le langage naturel.
La tokenisation
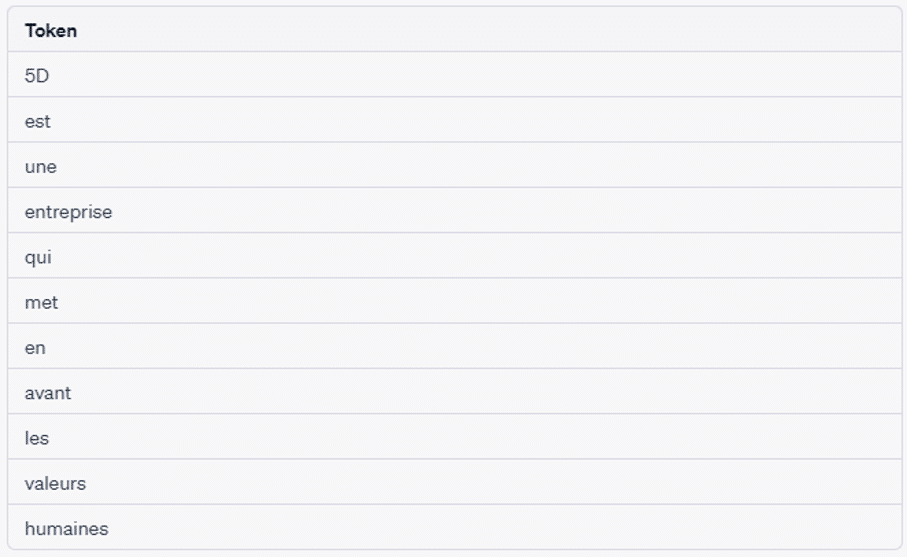
La tokenisation est le processus de décomposition d’un texte en unités individuelles, généralement des mots ou des phrases. Ces unités sont appelées “tokens“. La tokenisation est une étape cruciale du NLP car elle permet de simplifier les données pour l’analyse. Il existe différentes méthodes, telles que la tokenisation des espaces blancs, la tokenisation par expression régulière et la tokenisation basée sur des règles.
Exemple : “5D est une entreprise qui met en avant les valeurs humaines“.
La suppression des mots vides
Les mots vides sont des mots qui n’ont pas beaucoup de sens dans une phrase, comme “le“, “un” et “une“. En NLP, les mots vides sont généralement supprimés du texte parce qu’ils peuvent causer du bruit et affecter la précision de l’analyse. Il existe de nombreuses bibliothèques qui fournissent des listes prédéfinies de mots vides dans différentes langues et qui peuvent être utilisées pour les supprimer du texte.
Exemple : “5D est une entreprise qui met en avant les valeurs humaines“.
Suppression des mots blancs : “5D entreprise met valeurs humaines“.
Dénombrement et lemmatisation
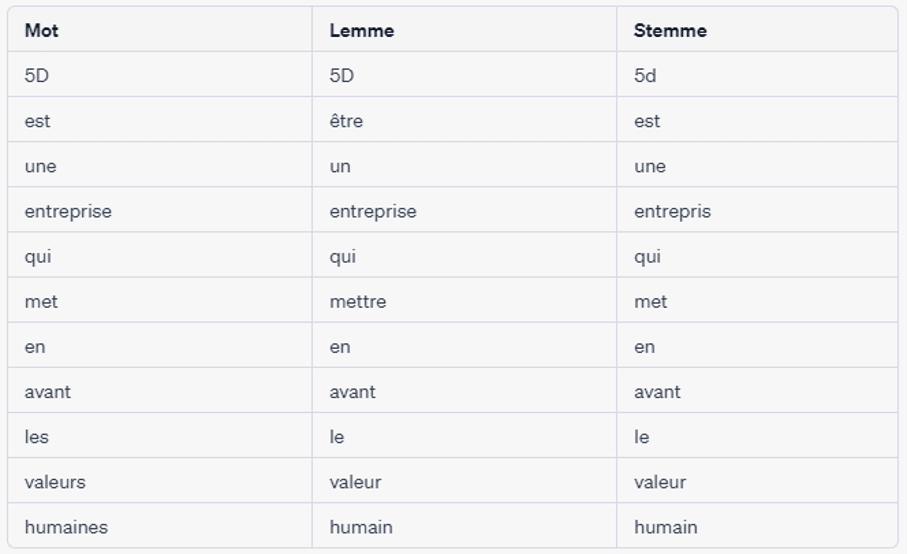
Le troncage (stemming en anglais) et la lemmatisation sont des techniques utilisées pour réduire les mots à leur forme de base. Le troncage consiste à supprimer les suffixes d’un mot pour le réduire à sa forme racine en supprimant tout suffixe ou préfixe. Par exemple, la racine du mot “danser” serait “danse“. La lemmatisation, quant à elle, consiste à réduire les mots à leur forme de base (comme dans un dictionnaire) en tenant compte de la partie du discours. Par exemple, le lemme du mot “course” serait “cour“. Contrairement au troncage, la lemmatisation ne se contente pas uniquement de supprimer les suffixes et les préfixes, elle analyse le mot en se basant sur le POS (partie du discours, ou part of speech en anglais), ce qui permet de prendre en compte le contexte d’évocation du mot. De plus, la lemmatisation réduit le mot à une forme qu’on peut trouver dans un dictionnaire.
Exemple : “5D est une entreprise qui met en avant les valeurs humaines“.
La reconnaissance d' entités nommées
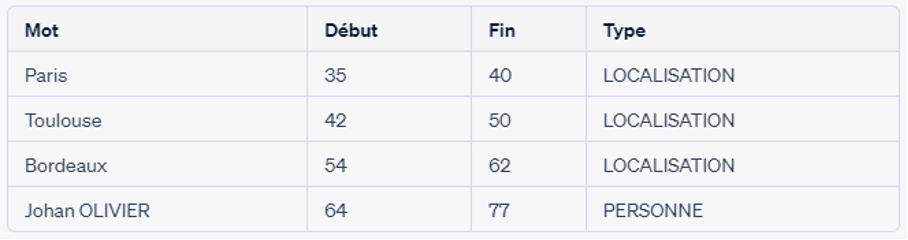
La reconnaissance des entités nommées (NER) est une technique utilisée pour identifier et extraire des entités telles que des personnes, des lieux et des organisations à partir d’un texte. La NER peut être utilisée pour extraire des informations à partir de grands volumes de texte, tels que des articles d’actualité ou des messages sur les médias sociaux. La NER peut également être utilisée pour l’analyse des sentiments, car l’identification des entités nommées peut fournir un contexte au sentiment exprimé dans une phrase.
Exemple : “5D est une entreprise basée à Paris, Toulouse et Bordeaux, Johan OLIVIER est un de ces Directeurs” .
L'étiquetage de la partie du discours
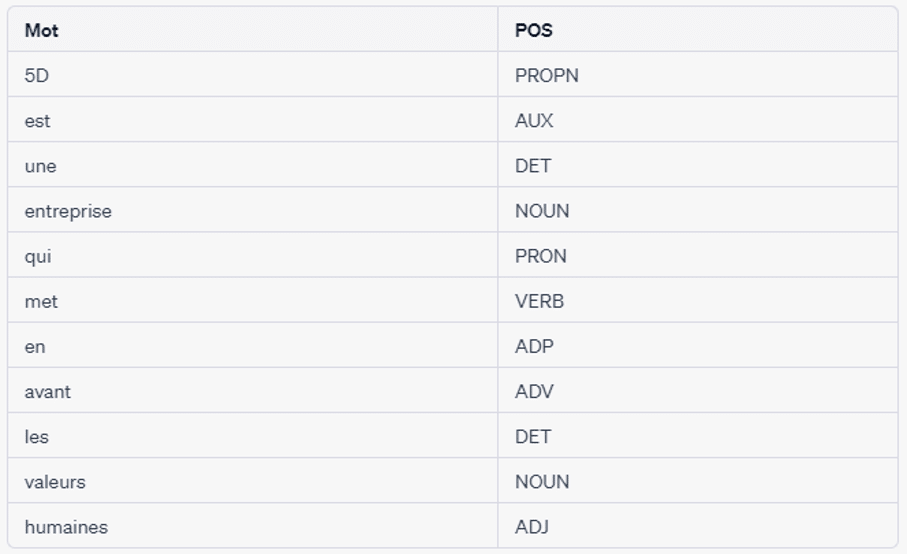
L’étiquetage des parties du discours, ou part of speech (POS) en anglais, est le processus d’étiquetage de chaque mot d’une phrase avec la partie du discours correspondante. Les parties du discours comprennent les noms, les verbes, les adjectifs, les adverbes et les pronoms. L’étiquetage POS est utilisé pour extraire des informations sur la structure d’une phrase, qui peuvent être utilisées dans des applications telles que la synthèse vocale et la traduction automatique.
Exemple : “5D est une entreprise qui met en avant les valeurs humaines“.
Quelques définitions utiles :
Représentation vectorielle
Le prolongement lexical, aussi appelé Word Embedding en anglais, permet d’encoder l’ensemble des sémantiques d’un terme du vocabulaire (lexique) sous la forme d’un vecteur de réel. Ces vecteurs sont le résultat d’un apprentissage non supervisé sur une grande quantité de donnée textuelles. Pour ce faire, il existe deux types d’approches : Bag of Words permet d’apprendre la sémantique du mot à partir de son contexte d’évocation (c’est-à-dire des mots qui l’entourent). Tandis que l’approche Skip Gram permet de prédire le contexte d’un mot.
Analyse des sentiments
L’analyse des sentiments est le processus d’analyse d’un texte afin de déterminer le sentiment qui y est exprimé. L’analyse des sentiments est utilisée dans des applications telles que l’analyse de la satisfaction client (avis client) ou l’analyse de contenu publié sur des médias sociaux (détection de discours haineux ou raciste). Il existe différentes techniques d’analyse des sentiments, telles que les techniques basées sur des règles, sur l’apprentissage automatique et sur des lexiques.
Chez 5 Degrés, nous intervenons chez nos clients pour enrichir leurs métadonnées.
Un exemple : nous sommes intervenus sur la mise en place de solutions d’analyse automatique de fils de news pour des agences de presse et des journaux. Leur problématique : traiter une grande quantité d’informations en temps réel.
Vous rencontrez des besoins similaires ? Vous cherchez un partenaire de confiance pour vous accompagner sur vos différentes problématiques Data ? Contactez-nous !
FAQ - Les Techniques NLP
Le NLP permet aux machines de comprendre, analyser et générer du langage humain. Il est utilisé dans les assistants vocaux, les chatbots, l’analyse de sentiment, la classification de texte ou encore la traduction automatique.
Pas forcément. Des bibliothèques accessibles comme SpaCy, NLTK ou HuggingFace permettent d’expérimenter sans expertise poussée. La compréhension des bases suffit pour débuter.
Biais des modèles, compréhension approximative du contexte, difficultés sur les nuances culturelles et nécessité de grandes quantités de données pour l’entraînement.
Cela dépend de l’objectif : classification, extraction d’entités, résumé automatique, génération de texte… Chaque usage a ses modèles adaptés.

Amine Medad
Consultant Data Scientist Practice Product Data


